Поделиться
Поделиться
Больше всего российским аналитикам не хватает навыка в презентации данных
Специалисты корпоративной образовательной платформы «Грейд» от «Яндекс практикума» опросили CTO крупного бизнеса и узнали, какие пробелы в знаниях аналитиков данных из своих команд они видят. Больше всего дата-аналитикам недостает навыка в презентации результата анализа данных, этот пробел отметили 85% опрошенных руководителей. Об этом CNews сообщили представители «Яндекса».
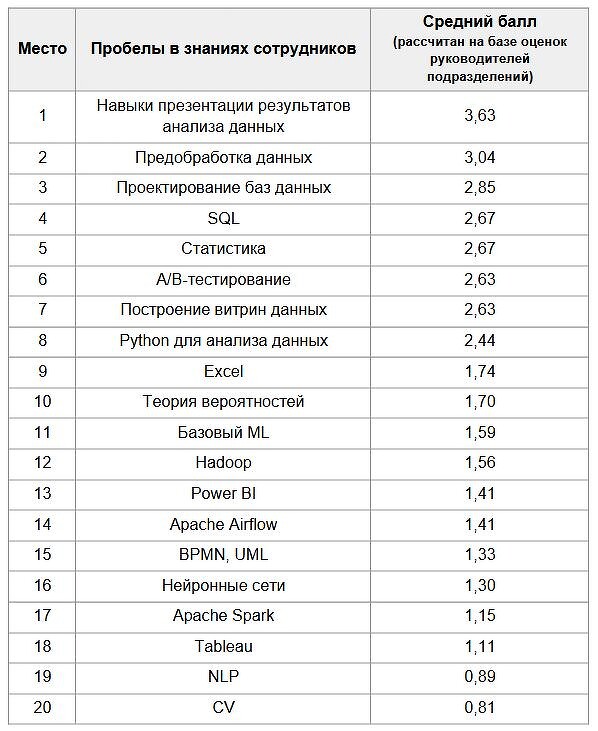
На основании оценок респондентов аналитики «Грейда» проранжировали 20 цифровых навыков специалистов по анализу данных с точки зрения их нехватки у кадров и составили рейтинг пробелов в знаниях. Так, первым в рейтинге «проблемных» навыков у дата-аналитиков оказалось умение презентовать данные — коэффициент нехватки составил 3,63 балла из 5.
«Примечательно, что больше всего дата-аналитикам не хватает навыка из категории софт-скиллз. Презентация результатов анализа данных — компетенция, которую специалисты редко развивают сознательно, тогда как технические пробелы сотрудники чаще всего стремятся закрыть курсами для апскиллинга или повышения квалификации. Зачастую именно от навыка аргументировать стейкхолдерам зависит то, насколько убедительно выглядят выводы, сделанные на основе анализа данных, для сотрудников бизнес-подразделений», — сказала Галина Лебедова, руководитель В2В-направления «Яндекс практикума».
Кроме того, среди наиболее значимых пробелов в умениях дата-аналитиков оказалась предобработка данных (преобразование необработанной информации в понятный формат и ее подготовка к анализу, от этого зависит правильно ли сработают аналитические алгоритмы и насколько достоверным будет результат) — коэффициент нехватки составил 3,04 балла из 5.
Также в тройку «проблемных» направлений попал навык проектирования баз данных (2,85 баллов из 5), то есть умение систематизировать масштабные массивы информации и создавать схемы систем управления данными.
Меньше всего российские аналитики данных нуждаются в навыках NLP (от англ. Natural Language Processing или «обработка естественного языка») и CV (от англ. Computer Vision или «компьютерное зрение») — средний коэффициент нехватки составил 0,89 и 0,81 из 5, основываясь на мнении руководителей и тимлидов из сферы анализа данных.
 Короткая ссылка
Короткая ссылка