

 Поделиться
Поделиться
Как ИИ помогает монетизировать большие данные
Сможет ли искусственный интеллект заменить инженеров на стройке, зачем на производстве роботы и дроны, почему почти все проекты, связанные с внедрением искусственного интеллекта, проваливаются? Об этом говорили участники организованной CNews Conferences конференции «Искусственный интеллект 2022». Представители разных сфер бизнеса и промышленных отраслей рассказали, как используют машинное обучение и ботов в своей практике.
Как обучить искусственный интеллект
Рынок искусственного интеллекта и машинного обучения стремительно развивается. Об этом в своем докладе говорил Отари Меликишвили, лидер продуктового направления SberCloud. Так, например, только в США количество вакансий в сфере машинного обучения выросло на 417%.
Представители ИТ-компаний отмечают, что благодаря ИИ точность прогнозирования нагрузки на серверы выросла до 98%, в банках удалось снизить количество ручных операций в 10 раз, в нефтегазовой отрасли удалось повысить точность предсказания поломок до 70%. «В тоже время во многих индустриях готовые конечные сервисы в области ML недостаточно универсализированы для того, чтобы можно было их широко использовать. Поэтому многим компаниям нужно создавать эти сервисы «под ключ», при том, что у них нет своих дата-сайентистов», — отметил Отари Меликишвили. Он предложил воспользоваться возможностями платформы ML Space от SberCloud. По его словам, это самый быстрый способ внедрения машинного обучения.
Платформа помогает строить и развертывать модели, обучать их и управлять параметрами такого обучения. ML Space — это комплексное решение проблем, возникающих при разработке моделей для машинного обучения, так как большие данные и ML неразделимы. Пользователи платформы отмечают серьезный рост скорости поставки изменений в ML-сервисах.
Рынок технологий искусственного интеллекта машинного обучения

Темы современной инфраструктуры для машинного обучения и искусственного интеллекта коснулся Тимофей Захаренко, ведущий менеджер по развитию бизнеса Selectel. У компании есть и облачное хранилище, и облачная платформа Vscale, и приватные облака, но если клиентам нужна еще большая защищенность, Selectel идет навстречу. «Все говорят про облака, но многие наши клиенты выбирают выделенные сервера в виде отдельно вынесенной площадки, которую нельзя назвать облаком. Она еще более безопасна — там можно хранить персональные данные», — отметил он.
Высокопроизводительный кластер на GPU

Еще одно предложение компании — конструктор, которые дает возможность собрать кастомизированный HPC-кластер для решения высокопроизводительных задач. При этом все заботы по его сборке и обслуживанию Selectel берет на себя.
Области применения ИИ
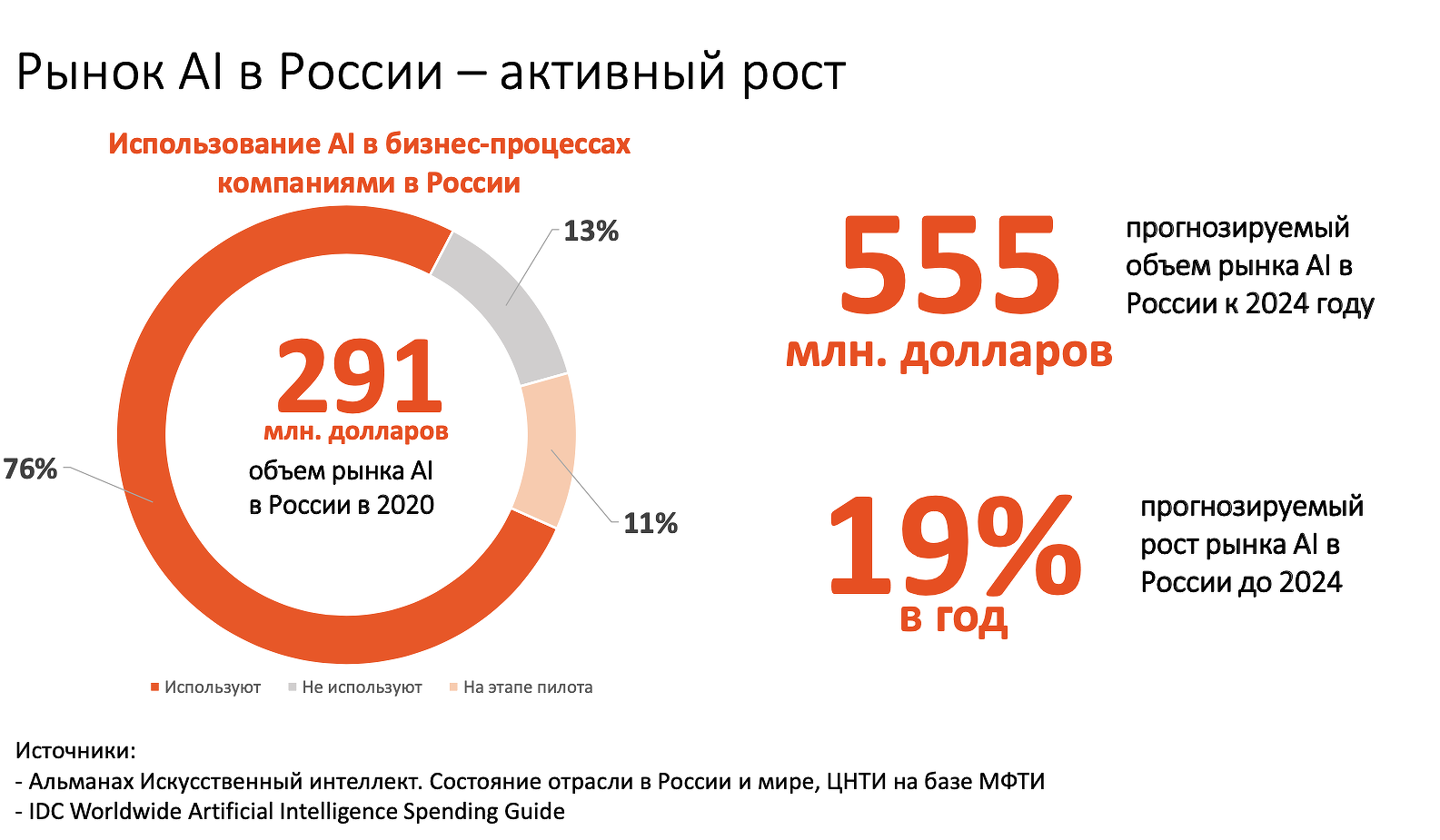
Объем рынка искусственного интеллекта в России в 2020 г. составлял $291 млн. По прогнозам IDC, к 2024 году он достигнет $555 млн. Искусственный интеллект становится ключевым элементом цифровой трансформации. «Почему в России такие решения пользуются спросом? Мне кажется, во многом потому, что потребители поменяли свое поведение: они стали более требовательны к сервисам. Результаты исследований говорят, что 80% клиентов готовы платить именно за сервис, а не за бренд, при этом треть уходит от любимого бренда при первой же ошибке с его стороны», — говорит Сергей Алешкин, глава департамента Data Science, СОГАЗ.
Рынок ИИ в России
Бизнес использует ИИ на каждом этапе взаимодействия с клиентами, и страховой рынок — не исключение. В кросс-продажах умные алгоритмы сразу отбрасывают 98% незаинтересованных людей, а 40% покупателей из тех, что были отобраны с помощью ИИ, готовы приобрести услугу добровольного страхования в ближайшее время. В результате трудозатраты сети на кросс-продажи снижаются в 30 раз.
Чтобы внедрение ИИ в компании прошло успешно, докладчик посоветовал начинать с процессов, где эта технология может принести максимальный эффект. При этом модели следует строить быстро, неудачные не жалеть, потому что из подготовленных десяти удачными будут только одна или две. Модели должны быть легкоинтерпретируемые, кроме того, не стоит забывать и о постоянном отслеживании их качественных метрик — в противном случае качество прогноза модели может критично снизиться.
Василий Ежов, владелец продукта IoT, СИБУР, отметил, что в его компании ИИ используется как в бизнес-сфере, так и на производстве. Применения в первой области у всех похожи, поэтому спикер решил остановиться на второй. Здесь строятся предиктивные модели, позволяющие на основе большого количества данных о технологическом процессе предсказывать выход оборудования из строя, минимизировать простои и потери. Кроме того, создаются цифровые двойники, чтобы экспериментировать и узнавать, что будет, если случится событие икс или игрек. Еще одна задача ИИ — давать экономические рекомендации.
Данные для всех этих моделей собираются с большого числа производственных систем: IoT, роботов, дронов, камер интеллектуального видеонаблюдения, АСУ ТП и так далее. Все они собираются в корпоративное хранилище данных. За счет использования моделей данных, собранных инструментами IIoT для оптимизации процессов производства, уже получен прямой экономический эффект — около ₽20 млн в год. А оснащение реактора беспроводными датчиками контроля температуры на стенках позволило своевременно обнаруживать локальные перегревы и не допустить остановки. «За 5 лет решение помогло избежать потерь в 200 млн рублей, и это только один кейс», — подчеркнул Василий Ежов и привел подробности методики расчета, которая многих интересовала.
Компьютерное зрение используют не только в магазинах и беспилотниках. О том, что может «увидеть» искусственный интеллект в строительстве, рассказал Георгий Банчиков, директор по продажам, Constru. Мы уже привыкли к технологиям в банке или в собственном телефоне. Но есть такая область, где всё до сих пор делается вручную. «Например, мало кто может с первого раза принять квартиру после отделки в новостройке. Щели, треснутые стеклопакеты — все требует доработок. В итоге ты просто плюешь и подписываешь акт приема-передачи, заселяешься и начинаешь тратить деньги на дополнительный ремонт. Проблема стройки в том, что на объектах огромное количество микрокоманд, занимающихся ручным неквалифицированным трудом. При этом за последние 30 лет производительность труда тут сократилась на 20 процентов», — говорит Георгий Банчиков.
 Отари Меликишвили, лидер продуктового направления, SberCloud: во многих индустриях готовые конечные сервисы в области ML недостаточно универсализированы для того, чтобы можно было их широко использовать. Поэтому многим компаниям нужно создавать эти сервисы «под ключ», при том, что у них нет своих дата-сайентистов
Отари Меликишвили, лидер продуктового направления, SberCloud: во многих индустриях готовые конечные сервисы в области ML недостаточно универсализированы для того, чтобы можно было их широко использовать. Поэтому многим компаниям нужно создавать эти сервисы «под ключ», при том, что у них нет своих дата-сайентистов
 Тимофей Захаренко, ведущий менеджер по развитию бизнеса, Selectel: Все говорят про облака, но многие наши клиенты выбирают выделенные сервера в виде отдельно вынесенной площадки, которую нельзя назвать облаком. Она еще более безопасна — там можно хранить персональные данные
Тимофей Захаренко, ведущий менеджер по развитию бизнеса, Selectel: Все говорят про облака, но многие наши клиенты выбирают выделенные сервера в виде отдельно вынесенной площадки, которую нельзя назвать облаком. Она еще более безопасна — там можно хранить персональные данные
 Сергей Алешкин, глава департамента Data Science, СОГАЗ: Почему в России такие решения пользуются спросом? Мне кажется, во многом потому, что потребители поменяли свое поведение: они стали более требовательны к сервисам
Сергей Алешкин, глава департамента Data Science, СОГАЗ: Почему в России такие решения пользуются спросом? Мне кажется, во многом потому, что потребители поменяли свое поведение: они стали более требовательны к сервисам
 Василий Ежов, владелец продукта IoT, СИБУР: Оснащение реактора беспроводными датчиками контроля температуры на стенках позволило своевременно обнаруживать локальные перегревы и не допустить остановки. За 5 лет решение помогло избежать потерь в 200 млн рублей, и это только один кейс.
Василий Ежов, владелец продукта IoT, СИБУР: Оснащение реактора беспроводными датчиками контроля температуры на стенках позволило своевременно обнаруживать локальные перегревы и не допустить остановки. За 5 лет решение помогло избежать потерь в 200 млн рублей, и это только один кейс.
 Георгий Банчиков, директор по продажам, Constru: Проблема стройки в том, что на объектах огромное количество микрокоманд, занимающихся ручным неквалифицированным трудом. При этом за последние 30 лет производительность труда тут сократилась на 20%
Георгий Банчиков, директор по продажам, Constru: Проблема стройки в том, что на объектах огромное количество микрокоманд, занимающихся ручным неквалифицированным трудом. При этом за последние 30 лет производительность труда тут сократилась на 20%
Для постоянного строительного контроля требуются тысячи инженеров на строительной площадке. Чтобы не раздувать штат, можно использовать виртуального инженера. Constru — платформа на базе компьютерного зрения — собирает, анализирует и визуализирует данные со стройки, формирует достоверный статус работ. Данные доступны как в ретроспективе, так и в режиме реального времени. Фотографии сравниваются с BIM-моделью автоматически. Если найдены несоответствия — это будет отражено в отчете. Общая статистика несоответствий показана в наглядном виде.
Ярослав Кабаков, директор по стратегии, ИК «ФИНАМ», предложил порассуждать, способен ли искусственный интеллект обеспечить счастье клиента. Машинное обучение и ИИ все больше внедряются в процессы управления финансами, а цифровые технологии лежат в основе всех взаимодействий с клиентами. «Но цифра не сможет обеспечить счастье клиента, если нет желания менеджмента», — подчеркнул докладчик.
В финансовой сфере за последние несколько лет появилось огромное количество инструментов. При этом сюда приходит много инвесторов-новичков, которые не очень представляют себе, что такое фондовый рынок и как быть с рисками. «Мы проводили тестирования и обратили внимание, что люди завышают собственные ожидания, а потом, когда опыт не соответствует этим ожиданиям, человек становится несчастен», — констатировал Ярослав Кабаков.
Цикл работы ИИ в «ФИНАМ»

Вторая проблема — у менеджеров существует собственное представление о том, что нужно предлагать клиенту и как его осчастливить. «Для того, чтобы менеджеру это удалось, его профессионализм должен быть очень высок, а это нарабатывается долго», — заметил спикер и рассказал, что в «ФИНАМ» создали и используют «индекс счастья». Этот показатель напрямую зависит от уровня использования технологий искусственного интеллекта. ИИ помогает подбирать не только финансовые продукты, но и рекомендует правильное время и канал коммуникации для их предложения. Тут важно не перегрузить человека информацией, сделать все аккуратно.
Поболтаем с ботом?
Условия успешного внедрения ИИ в процесс коммуникации с пользователем перечислил Марат Девликамов, исполнительный директор, TWIN. «Мы провели оценку и выяснили, что голосовое общение обычного специалиста, отвечающего за коммуникации, стоит 35-45 рублей за минуту диалога. Некоторые компании считают, что их минута стоит 2 рубля — это вопрос методологии расчетов. В наш расчет мы закладываем и величину зарплаты работника, и расходы на офис и оборудование, и даже пластиковые стаканчики у него на столе».
С одной стороны, компании пытаются оптимизировать расходы, с другой — телефон давно уже не единственное средство общения с клиентами. Новые каналы связи нужно использовать эффективно. И технологии позволяют это сделать. Так, например, точность распознавания речи выросла с 70 до 96%, синтез речи занимает не 40 часов, а час, да и клиенты, в общем-то, созрели. Большая часть столичных жителей и половина людей из регионов уже готовы общаться с роботом.
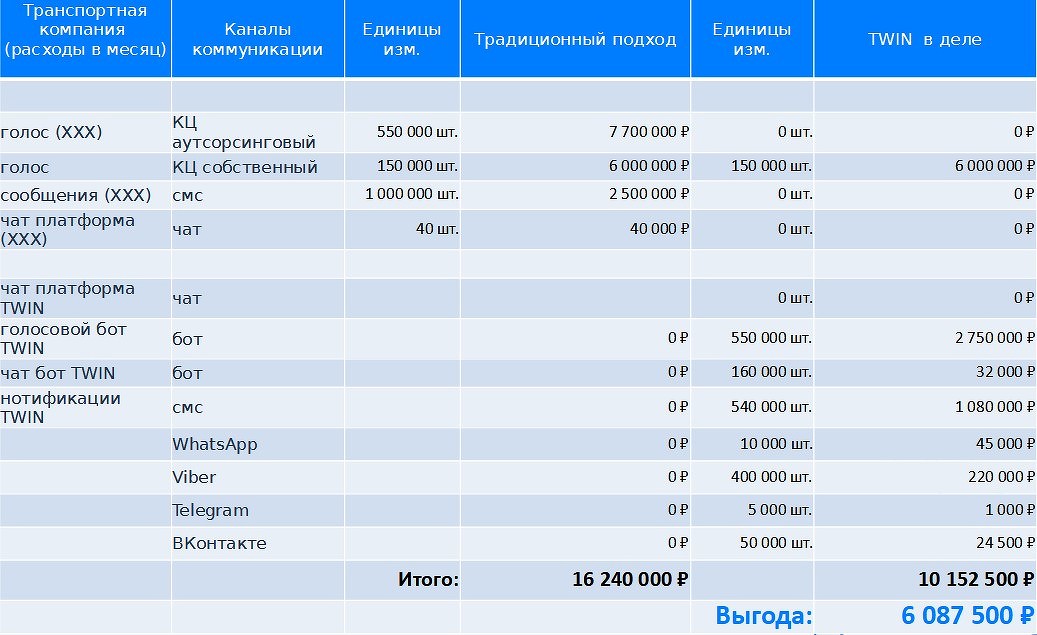
Использование омниканальной платформы Twin позволяет распределить коммуникации по разным каналам и сэкономить за месяц ₽6 млн. Спикер привел подробную таблицу с расчетами, чтобы обосновать именно такую сумму экономии. При традиционном подходе к коммуникациям (смс плюс колл-центры) компании тратят, обычно, по ₽16 млн в месяц.
Как добиться экономии
Нейросеть постоянно обучается: улучшает формулировки и запоминает наиболее частые запросы, то есть решение слышит собеседника и понимает, если что-то идет не так. Говоря о дальнейшем развитии ботов, Марат Девликамов вспомнил запрос от европейской компании, которая планирует каждый день напоминать людям с болезнью Альцгеймера подробности их жизни, которые они постоянно забывают. Бот расскажет больному, где тот живет, сколько у него родственников, как их зовут и всё, что необходимо знать о себе пациенту, чтобы снизить уровень тревожности. «Это не совсем рыночный кейс, но возможность применения технологии», — сказал докладчик.
Голос в два раза дороже чатов, а качество синтеза и распознавания речи в последние годы значительно улучшились, говорит Илья Щиров, директор направления автоматизации цифрового взаимодействия с клиентами, Райффайзенбанк. «Мы проводили тесты, в первую очередь, на входящей линии. Никаких негативных оценок, клиентов вполне устраивает синтез голоса. Запись лучше, но синтез тоже ничего», — сказал он.
Чтобы добиться экономии, в банке были автоматизированы как входящая, так и исходящая линия. Вендорские варианты показались слишком дорогими или, если речь об облачном варианте, слишком проблемными с точки зрения персональных данных, поэтому было разработано собственное решение, а
Автоматизация исходящей линии

После первого запуска, который состоялся в сентябре 2021 г., было сделано 1000 тестовых звонков. Процент дозвона составил 82%. «Мы сравнивали с лучшими вендорскими решениями по обзвону. Наш процент совершенно нормальный, нас это порадовало», — поделился опытом докладчик. Ошибок тоже было мало — не больше 1%, но возникла проблема с конверсией. Причину обнаружили в бизнес-процессах, в программных кусках от вендора, а также в самом дата-сете. Кроме того, оказалось, что нужно было по-разному использовать нейросети для входящей и исходящей линий. Последняя требовала моделей попроще.
После исправления всех ошибок оказалось, что собственное решение в 4 раза дешевле, чем вендорское, а его конверсия на 15% выше. В планах — добиться еще большего процента дозвонов.
«Новая нефть» или провал?
Данные — это фундамент любой технологии. «Новая нефть», как их называют сегодня. Но как оценить качество дата-сетов? «За 6 лет опыта работы дата-сайентистом я вычленил три критерия для проведения качественной оценки любого дата-сета», — говорит Георгий Каспарьянц, основатель и генеральный директор LabelMe.
Во-первых, нужно проверить, не являются ли данные «сырыми», то есть неоднородными, с ошибками и пропусками. Такие вещи случаются, если разметчики используют разный софт, данные не прошли финальную проверку или их подготовкой занимались люди без нужного опыта и навыков. Во-вторых, стоит проверить данные на качество. Качество данных зависит от их разметки. Наконец, данные могут быть и качественными, и не сырыми, а технология не работает. Почему? Потому что данные неполные. Дата-сет не покрывает все кейсы используемой технологии или же дата-инженеры допустили ошибки при работе с ними.
 Ярослав Кабаков, директор по стратегии, ИК «ФИНАМ»: Машинное обучение и ИИ все больше внедряются в процессы управления финансами, а цифровые технологии лежат в основе всех взаимодействий с клиентами. Но цифра не сможет обеспечить счастье клиента, если нет желания менеджмента
Ярослав Кабаков, директор по стратегии, ИК «ФИНАМ»: Машинное обучение и ИИ все больше внедряются в процессы управления финансами, а цифровые технологии лежат в основе всех взаимодействий с клиентами. Но цифра не сможет обеспечить счастье клиента, если нет желания менеджмента
 Марат Девликамов, исполнительный директор, TWIN: Мы провели оценку и выяснили, что голосовое общение обычного специалиста, отвечающего за коммуникации, стоит 35-45 рублей за минуту диалога
Марат Девликамов, исполнительный директор, TWIN: Мы провели оценку и выяснили, что голосовое общение обычного специалиста, отвечающего за коммуникации, стоит 35-45 рублей за минуту диалога
 Илья Щиров, директор направления автоматизации цифрового взаимодействия с клиентами, Райффайзенбанк: Мы проводили тесты, в первую очередь, на входящей линии. Никаких негативных оценок, клиентов вполне устраивает синтез голоса. Запись лучше, но синтез тоже хорошо
Илья Щиров, директор направления автоматизации цифрового взаимодействия с клиентами, Райффайзенбанк: Мы проводили тесты, в первую очередь, на входящей линии. Никаких негативных оценок, клиентов вполне устраивает синтез голоса. Запись лучше, но синтез тоже хорошо
 Георгий Каспарьянц, основатель и генеральный директор LabelMe: За 6 лет работы дата-сайентистом я вычленил три критерия для проведения качественной оценки любого дата-сета: данные не должны быть сырыми, некачественными и неполными
Георгий Каспарьянц, основатель и генеральный директор LabelMe: За 6 лет работы дата-сайентистом я вычленил три критерия для проведения качественной оценки любого дата-сета: данные не должны быть сырыми, некачественными и неполными
 Адель Валиуллин, исполнительный директор департамента анализа данных и моделирования, Газпромбанк: Запуская проект с ИИ, мы должны сразу понимать, будет ли экономический эффект
Адель Валиуллин, исполнительный директор департамента анализа данных и моделирования, Газпромбанк: Запуская проект с ИИ, мы должны сразу понимать, будет ли экономический эффект
 Юрий Сирота, независимый эксперт: Сегодня все говорили про то, что надо собрать побольше данных и положить их в кладовку. Но мне не нравится этот термин: большие данные. Что это такое: петабайты или то, что не влезает в оперативную память?
Юрий Сирота, независимый эксперт: Сегодня все говорили про то, что надо собрать побольше данных и положить их в кладовку. Но мне не нравится этот термин: большие данные. Что это такое: петабайты или то, что не влезает в оперативную память?
Чтобы избежать всего вышеперечисленного, в LabelMe собирают бесплатный тестовый дата-сет, изучают техзадание от клиента, проверяют разметку на каждом этапе работы, а к делу допускают только опытных сотрудников. Вся работа происходит в единой системе для получения однородных результатов.
Скоро будет сложно представить области, в которых не задействован искусственный интеллект. Адель Валиуллин, исполнительный директор департамента анализа данных и моделирования Газпромбанка, рассказал, что сейчас эту технологию легко встретить в поисковых системах, кредитном скоринге, системе рекомендаций, в предсказании поломок и так далее. При этом докладчик отметил, что внедрение проектов, связанных с ИИ, может нести с собой потери, в том числе репутационные, потому что примерно 85 проектов из ста оказываются неудачными.
«Запуская проект с ИИ, мы должны сразу понимать, будет ли экономический эффект. На самом деле, это довольно сложная задача — просчитать такой эффект. Лучше оцифровывать регулярный процесс, например, колл-центр с его одинаковыми ответами на одни и те же вопросы, а также иметь достаточное количество данных для машинного обучения. При этом, когда вы работаете с большим количеством данных, всплывает множество проблем», — сказал Адель Валиуллин.
Если вы столкнулись с неожиданностью — это первый признак неадекватной картины мира, привел слова одного известного бизнес-тренера Юрий Сирота, независимый эксперт, и предложил поговорить про плохие кейсы, потому что про хорошие и так слышно «из каждого утюга». А ведь успешных кейсов на самом деле не так много, не больше 5-10% от общего количества попыток.
«Сегодня все говорили про то, что надо собрать побольше данных и положить их в кладовку. Но мне не нравится этот термин: большие данные. Что это такое: петабайты или то, что не влезает в оперативную память? Гораздо эффективнее говорить про данные, имеющие большую ценность. А большая ценность может быть достигнута и маленькими данными», — говорит Юрий Сирота. Данные имеют ценность тогда, когда их проанализировали и на основе этого анализа совершили управленческие действия.
Искусственный интеллект пока слаб. То, что он может распознавать образы, речь или текст, говорит лишь о том, что автоматизированы частные задачи. Основная цель — монетизировать имеющиеся данные. «Посмотрите в свою отчетность. Это огромный источник идей по монетизации», — призвал эксперт. А вот строить корпоративные кладбища данных не стоит.



 Короткая ссылка
Короткая ссылка








